An AI-assisted workflow to find, explain, and fix critical a11y issues fast — with guardrails and concise code suggestions. Detects violations, maps them to WCAG, and emits the smallest possible HTML/CSS diff without breaking IDs, ARIA, or semantics.
An accessibility audit usually ends with a 200-page PDF and a Jira backlog of color-contrast tickets. Nothing actually gets fixed. This dashboard closes the loop: detect issues, explain why they matter, and provide copy-ready HTML/CSS with guardrails so engineers can ship faster without breaking semantics or brand.
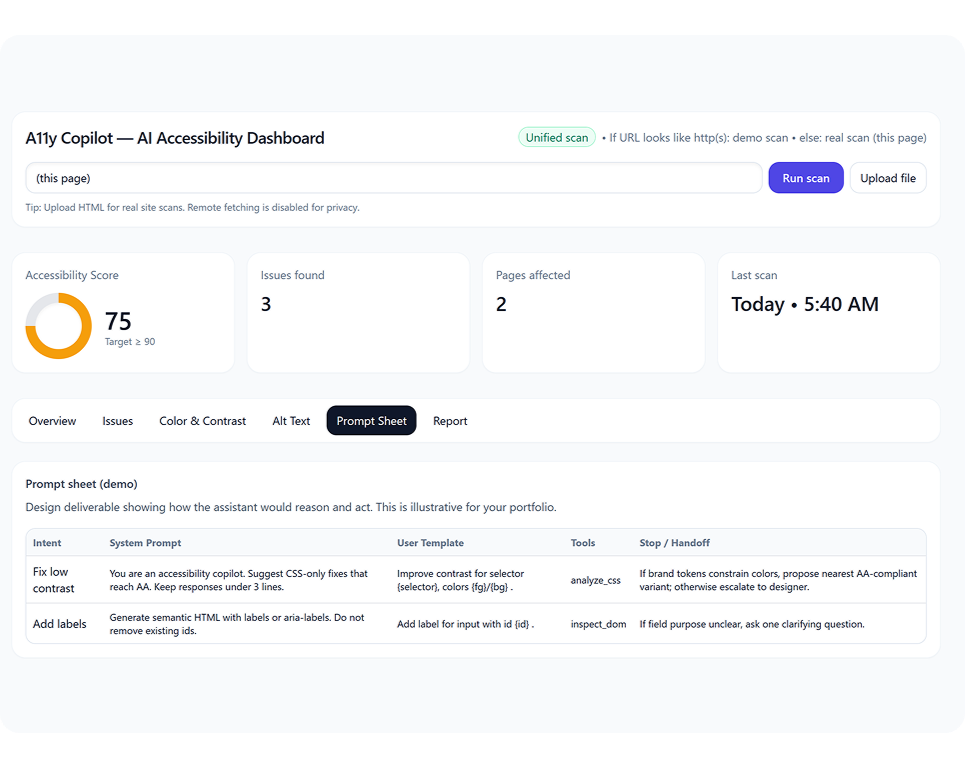
Score and trend lines surface the issues that affect real users now — not the long tail of WCAG nice-to-haves.
Each issue ships with a tiny HTML/CSS diff. IDs and ARIA preserved. No mass rewrites, no architecture changes.
One number that moves over time. PM can show progress to leadership without translating WCAG into business language.
Run axe-core for the deterministic baseline. Layer heuristic rules for issues axe doesn't catch (focus order quirks, ARIA misuse patterns, dynamic-content gotchas).
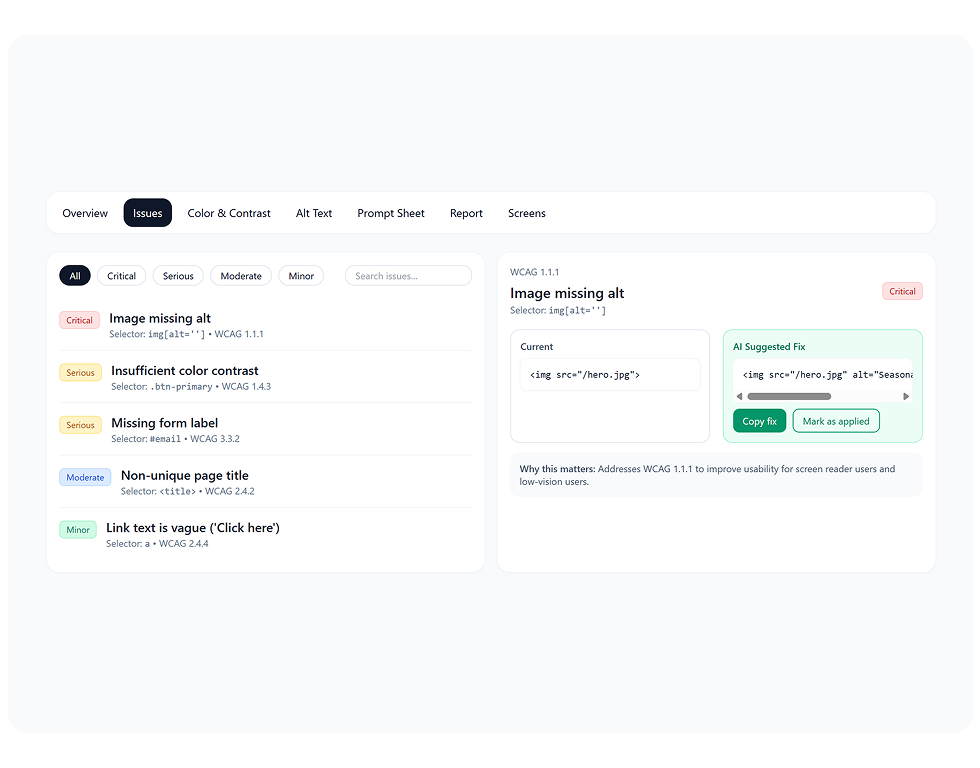
Each violation is mapped to a specific WCAG criterion and a plain-English explanation of why it matters. The LLM picks the safest minimal change for the violation type.
The proposal is copy-ready — usually 2–5 lines. No surrounding refactor. No rewrites of the component shell. Just the change the rule requires.
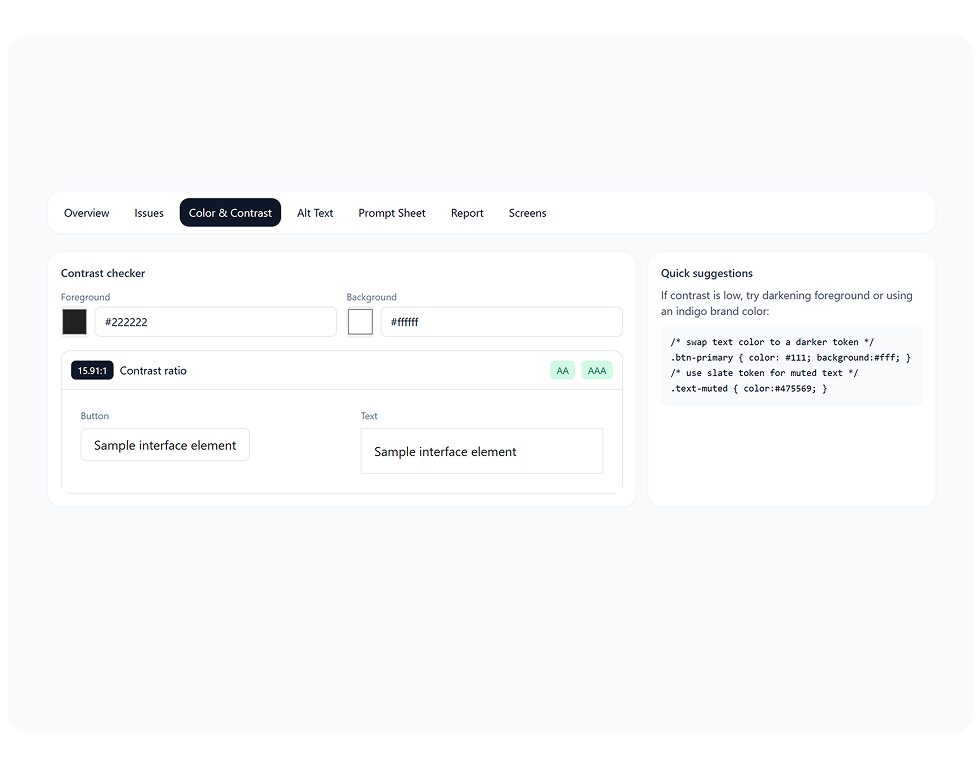
The LLM is prompt-bound to: never remove IDs, never strip ARIA, never propose a contrast value that isn't AA-compliant, snap to the nearest AA color in the user's token palette.
The dashboard never assumes a centralized service. Bring your own LLM key. Outputs are deterministic enough to run in CI on every PR — no flaky model-of-the-day. Adapter-based stack lets teams swap providers without rewriting flows.
Inputs (the HTML to audit) and outputs (the diff) are both schema-bound. The LLM is the translator, not the judge — its job is to map a violation to a known repair pattern. The repair pattern is plain code. The guardrails are constants, not prompts.
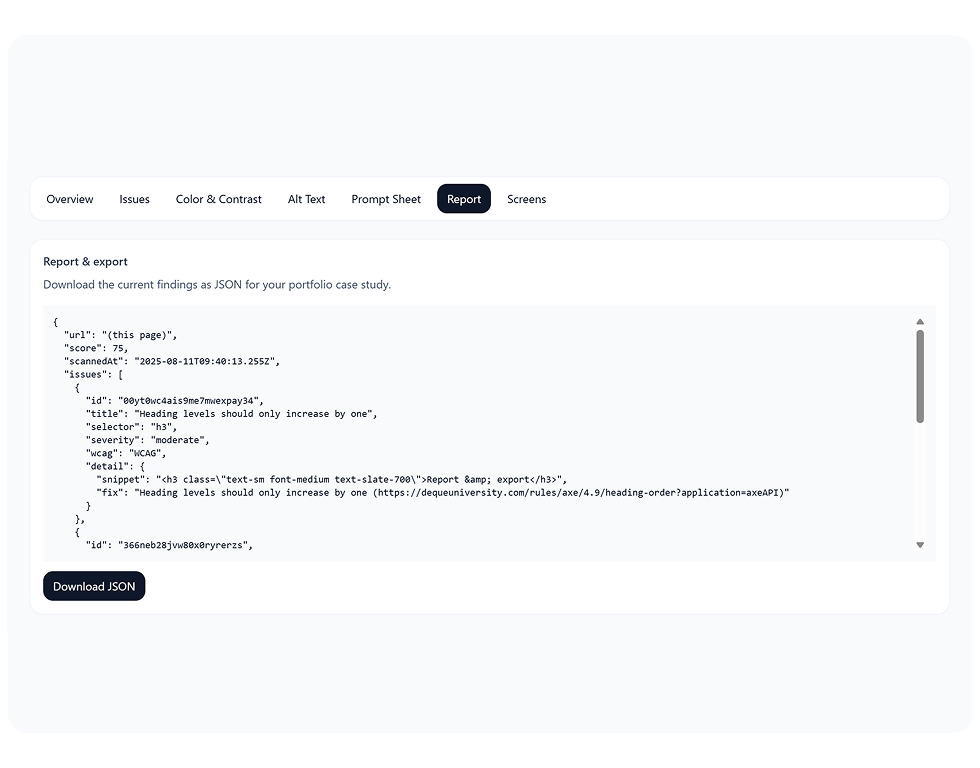
This case study itself is the proof. Every issue comes with a one-line WCAG rationale, a minimal diff, and a contrast preview. Nothing in the UI is decorative — it's all evidence.
Catalogued the most common violation patterns across the projects I'd worked on. Triaged by frequency × fix-cost — the top 12 patterns cover ~80% of issues.
Issues land in a triage queue ranked by severity. One-click to surface the smallest diff. Engineers copy the patch; designers see the contrast preview against design tokens.
Built a small token-aware design system so contrast suggestions snap to existing brand colors — engineers never paste a value that breaks the palette.
axe-core for deterministic detection. LLM call constrained by JSON schema. Every prompt unit-tested with adversarial inputs (broken HTML, missing tags, mixed casing).
Drop in a URL, the dashboard runs axe-core + heuristics on the live DOM, and a triaged issue list streams in. Click any issue → see the WCAG rationale, the proposed diff, the before/after contrast ratio, and a copy button.
Accessibility tooling has a credibility problem: it surfaces too much, fixes too little. A11y Copilot is my answer — surface less, propose more, and never break what the engineer already wrote. The guardrails are the product.
The bigger lesson, which carried into my later AI work: LLMs are excellent translators of intent into structured outputs, and they're dangerous judges of business rules. Here, the LLM translates "low contrast" into "snap to nearest AA token". The judgment of which colors are allowed lives in code — not in a prompt.